Triển khai Triton Inference Server trên Google Kubernetes Engine
Tại sao cần dùng Triton?
Khi triển khai mô hình Deep Learning lên môi trường K8S, chúng ta có thể áp dụng phương pháp giống như đối với các chương trình thông thường, về cơ bản thì sẽ gồm những bước như sau:
- Đóng gói code và mô hình vào Docker image.
- Đẩy image lên registry.
- Tạo deployment và service trên K8S.
- Tạo ingress nối đến service vừa tạo.
Phương pháp này rất đơn giản và hiệu quả đối với những mô hình gọn nhẹ không cần đến GPU, ví dụ như mô hình phân loại văn bản bằng LSTM, các mô hình Machine Learning truyền thống như SVM hay Random Forest. Nhưng khi mô hình lớn đến mức không đáp ứng được các yêu cầu về latency hoặc throughput thì triển khai lên GPU là điều cần thiết. Nếu chúng ta vẫn áp dụng phương pháp kể trên thì có những nhược điểm như sau:
- Các image dùng được GPU thường có kích thước lớn, cộng với việc mô hình cũng có kích thước lớn khiến cho image đầu ra nặng đến mức làm chậm đáng kể thời gian push và pull image trong quá trình triển khai. Điều này gây khó khăn nếu mô hình thường xuyên được cập nhật với dữ liệu mới.
- Kubernetes không cung cấp cơ chế native cho việc cấp phát 1 GPU cho nhiều container. Không giống như khi cấp phát CPU, container khi yêu cầu K8S cấp phát GPU chỉ có thể được cấp nguyên cả 1 GPU chứ không được yêu cầu 0.5 hay 0.1 GPU. Vấn đề này có thể được khắc phục nhờ vào một số giải pháp như multi-instance GPUs (chỉ hỗ trợ dòng A100) hoặc time-sharing GPUs, nhưng đều phải phụ thuộc vào giải pháp của bên thứ 3, đồng nghĩa với việc migrate sẽ phức tạp hơn (giả sử như bạn muốn chuyển qua AWS nhưng họ chưa hỗ trợ hoặc cung cấp giải pháp khác thì sao?).
Triton có thể giải quyết được những nhược điểm này. Nó là 1 phần mềm mã nguồn mở dành cho vai trò inference các mô hình Machine Learning, được tạo bởi đội ngũ của Nvidia. Triton cho phép triển khai nhiều mô hình đến từ nhiều framework khác nhau, bao gồm TensorRT, TensorFlow, PyTorch, ONNX, OpenVINO, Python, RAPIDS FIL,… Triton hỗ trợ nhiều hình thức truy vấn khác nhau, bao gồm truy vấn real time, theo batched, ensembles, và audio/video streaming. Chúng đều được tối ưu để có hiệu năng cao.
Vậy thì Triton giải quyết những vấn đề trên như thế nào?
- Khi triển khai Triton lên K8S, chúng ta không cần phải đóng gói image kèm với mô hình. Thay vào đó, mô hình được mount từ 1 file system vào 1 thư mục cụ thể, hoặc kết nối đến cloud storage như S3 hay GCS. Khi khởi động, Triton sẽ tải mô hình từ cloud storage về local và bắt đầu chạy. Vì thế nên kích thước của image sẽ nhẹ hơn và không cần phải pull lại image khi cập nhật mô hình mà chỉ cần tải lại file mô hình từ cloud storage.
- Cơ chế của Triton là quản lý tập trung nhiều mô hình khác nhau trong cùng 1 container. Trong đó, các mô hình có thể cùng chia sẻ tài nguyên của 1 GPU, giúp cho việc sử dụng GPU tối ưu hơn. Giải pháp của bên thứ 3 vì vậy trở nên không cần thiết nên việc migrate sẽ dễ dàng hơn.
Trong phần tiếp theo, mình sẽ hướng dẫn cách triển khai Triton trên Google Kubernetes Engine.
Triển khai Triton trên GKE
Trước khi bắt đầu triển khai, chúng ta hãy cùng phân tích kiến trúc của Triton trên GKE.
Kiến trúc tổng quan
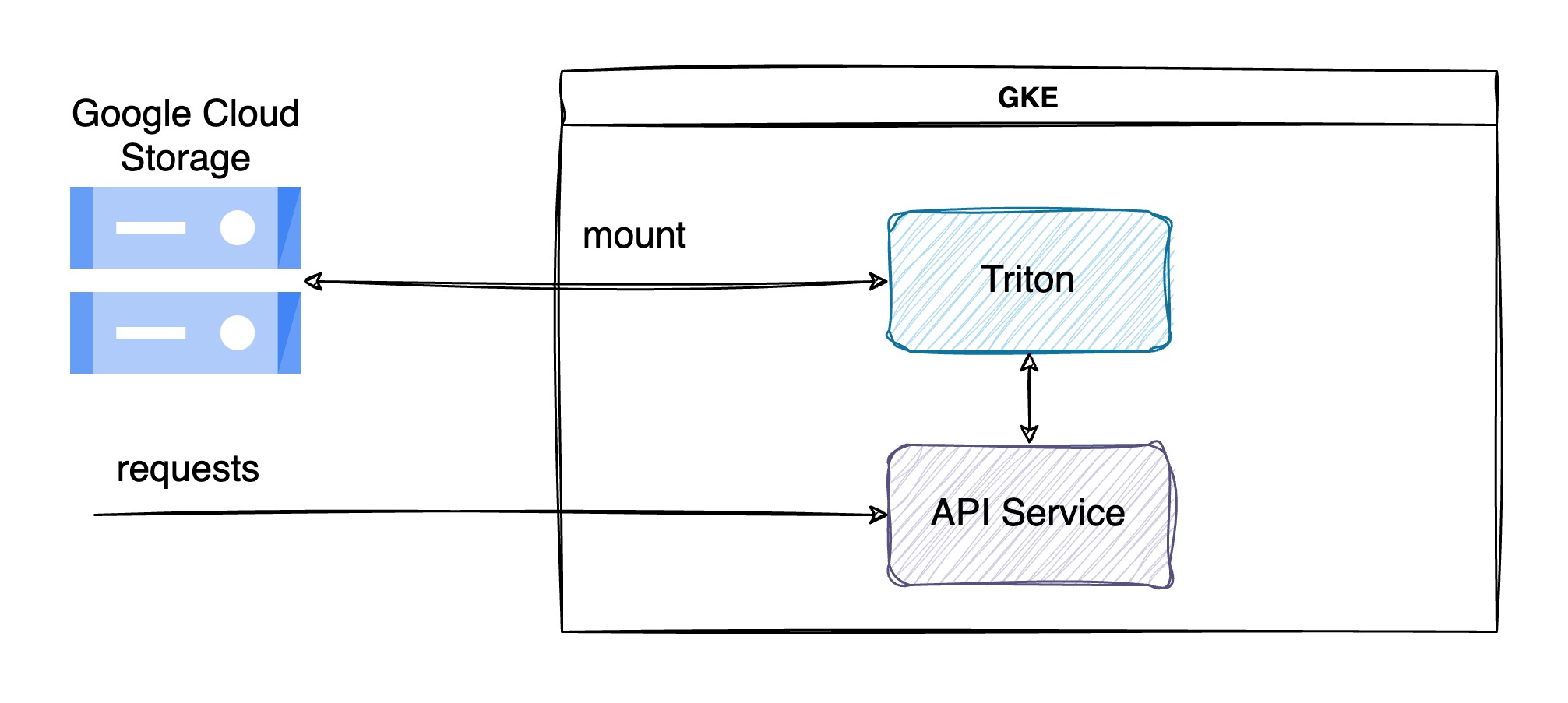
Như đã nói ở phần trước, Triton cần phải mount từ 1 file system hoặc cloud storage để có thể tải mô hình lên GPU. GKE đều cung cấp cả 2 cách mount này, nhưng mount từ file system sẽ gây khó khăn trong việc tải mô hình lên disk trong khi đó thì GCS cho phép tải, chỉnh sửa, xoá file một cách dễ dàng. Hơn nữa là chi phí của GCS rẻ hơn so với dùng disk, GCS tính phí theo phương án “dùng nhiêu trả nhiêu”, còn disk thì ta phải cấp phát lượng dung lượng nhất định không tránh khỏi dư thừa.
Mặc dù Triton cho phép chạy custom code Python để preprocess input và postprocess output, giúp cho nó có thể xử lý request từ đầu đến cuối. Nhưng theo mình thì Triton chỉ nên được sử dụng cho mục đích inference mô hình mà thôi. Các công đoạn như preprocess, postprocess, monitor nên được giao cho pod khác mà mình gọi là API Service trong hình trên. Như thế sẽ tách rời được vai trò giữa các service, theo nguyên tắc thiết kế của microservice.
API Service là nơi nhận request từ bên ngoài, preprocess, gửi data đến Triton, nhận kết quả inference, postprocess và trả kết quả về. Nó còn có nhiệm vụ theo dõi các metric như latency, request per second, throughput, confident score. Một lợi ích khác của việc phân tách vai trò là có thể scale một cách linh hoạt hơn. Giả sử như bạn có 1 module preprocess rất nặng và chậm, bạn có thể scale pod API Service trên 1 node khác không cần GPU nhưng có nhiều tài nguyên hơn mà không cần phải scale luôn cả Triton.
Tiến hành triển khai
Tạo GCS bucket
Việc đầu tiên chúng ta cần phải làm là tạo 1 bucket trên GCS. Nếu bạn đã có sẵn bucket rồi thì có thể bỏ qua phần này.
- Trong phần navigation, chọn Cloud Storage > Buckets.
- Click Create.
- Chọn tên cho bucket. Trong bài viết này mình sẽ giả sử tên của bucket là triton-models, nhưng bạn nên chọn tên khác vì tên bucket là globally unique. Trong các đoạn code bên dưới, bạn cần thay tên bucket giả sử với tên bucket mà bạn tạo.
- Trong mục control access, mình recommend bạn hãy giới hạn quyền truy cập vào bucket này bằng cách check vào ô Enforce public access prevention on this bucket. Nó sẽ ngăn model bị public ra bên ngoài.
- Click Create.
Tạo service account
Để Triton có thể truy cập vào bucket của GCS, chúng ta phải cung cấp cho nó key của service account có quyền truy cập vào GCS. Để làm điều này, trước tiên ta phải tạo service account có quyền Storage Admin. Chú ý là chỉ nên cấp 1 quyền này cho service account của bạn để giảm thiểu rủi ro an ninh.
- Truy cập vào IAM & Admin > Service Accounts.
- Click CREATE SERVICE ACCOUNT.
- Điền các thông tin cần thiết.
- Đến phần Grant this service account access to project, thêm quyền Storage Admin.
- Click Done.
Nếu bạn không có quyền để truy cập IAM & Admin > Service Accounts, bạn có thể nhờ admin của project để tạo thay.
Sau khi tạo xong service account, bạn chọn service account vừa tạo và chọn tab KEYS. Ở đây liệt kê các key dùng để authenticate với quyền của service account này, click vào ADD KEY và chọn Create new key, chọn key type là JSON và click CREATE.
Tải file key với tên là key.json về môi trường kubectl của bạn và dùng lệnh sau để tạo secret trên K8S:
1 | |
Secret này sẽ được mount vào container của Triton để authenticate với GCS.
Triển khai Triton
Dưới đây là cấu hình deployment của Triton:
1 | |
Copy đoạn code trên vào file deployment.yaml và chạy lệnh:
1 | |
Tiếp theo là tạo file service service.yaml:
1 | |
Tạo service bằng lệnh:
1 | |
Sau khi hoàn tất, bạn có thể gọi service triton từ các pod khác trong cluster thông qua endpoint triton:8000 đối với HTTP hoặc triton:8001 đối với GRPC.
Nếu muốn gọi trực tiếp Triton từ ngoài cluster thì bạn có thể tạo file ingress.yaml, nếu dùng NGINX Ingress Controller thì file cấu hình cơ bản sẽ tương tự như sau:
1 | |
Rồi dùng lệnh:
1 | |
Ingress này sẽ điều hướng request URL có prefix dạng http://<your-domain>/triton đến service triton vào port HTTP.
Chạy mô hình
Do bucket vừa mới tạo chưa có gì nên chúng ta chưa thể chạy được mô hình nào cả. Trước tiên, bạn cần đưa mô hình của bạn lên bucket theo đúng chuẩn do Triton quy định, tham khảo ở đây. Để diễn giải cho phần này, mình giả sử ở đây đang có 1 mô hình BERT cho bài toán phân loại văn bản.
Nếu bạn đã đọc document tham khảo của Triton, hãy thử xem qua file config của BERT:
1 | |
Để giao tiếp với Triton, có 2 protocol là HTTP và gRPC. gRPC có hiệu suất tốt hơn so với HTTP nên mình chọn protocol này cho code API Service. Triton cung cấp cho chúng ta thư viện Python để đơn giản hoá việc gọi mô hình (Github).
Dưới đây là đoạn code tham khảo để gọi mô hình BERT cho text classification:
1 | |
Đoạn code này chỉ là phần core của API Service, những thành phần khác như server, text preprocess, postprocess thì bạn tham khảo ở bên ngoài nhé.
Các vấn đề nảy sinh
Kích thước image còn khá lớn
Nếu bạn dùng spot node như mình thì hay xảy ra trường hợp bị downtime khá lâu khi node bị preemptible. Nguyên nhân chủ yếu là do image của Triton vẫn còn khá nặng nên thời gian pull về lâu. Có thể giảm kích thước của image bằng cách build custom image chỉ hỗ trợ framework mà bạn hay dùng, như của mình là ONNX nên có thể loại bỏ TF, PyTorch. Xem ở đây để tham khảo cách build custom image cho framework của bạn.
Tranh chấp tài nguyên giữa các mô hình
Hiện tại chưa có cơ chế giới hạn tài nguyên của mô hình nên nếu có 1 mô hình sử dụng hết tài nguyên của GPU thì các mô hình khác sẽ không thể chạy được.
Khó scale theo chiều ngang
Vì Triton quản lý mô hình theo hình thức tập trung, mỗi pod sẽ chứa ít nhất 1 instance của mỗi mô hình. Khi ta muốn scale 1 mô hình, nếu ta scale số lượng pod thì đồng nghĩa với việc scale tất cả mô hình còn lại, rất là lãng phí. Đối với scale theo chiều dọc thì sẽ dễ dàng hơn vì Triton cho phép tạo nhiều instance của 1 mô hình trên nhiều GPU, xem Instance Groups.
Tổng kết
Hi vọng sau bài viết này, bạn có thể triển khai mô hình của mình lên Triton trên GKE. Mặc dù bài viết này chỉ tập trung vào GKE, nếu bạn dùng AWS hay onprem thì cơ chế cũng gần tương tự nhau, chỉ cần 1 cloud storage giống như S3 hoặc GCS là có thể chạy được, và tất nhiên là cần GPU nữa.
Happy Coding!